Llama 3 Demo¶
This is an example demostrating how to train Llama 3 8B with nnScaler’s trainer.
The example contains one single script, train.py.
Get Started¶
Installation¶
Get your Hugging Face token to access Llama 3 model
export HF_TOKEN=...
Clone nnScaler repo
git clone --recursive https://github.com/microsoft/nnscaler
Install dependencies (including Llama 3 dependencies) and nnScaler from source
cd nnscaler pip install -r requirements.txt pip install -e .
Find the Llama 3 example
cd nnscaler/examples/llama3_demo
Prepare dataset
# To run Llama 3 8B: python train.py --prepare_data # Or to run a shrinked Llama for debug: python train.py --prepare_data --mini
Train a Mini-model¶
This examples requires 8 x 80GB GPU memory to train a full 8B model. If your have qualified GPUs, you can go to the next section.
Alternatively, you may start from a smaller model for verification:
python train.py --prepare_data --mini
torchrun --nproc_per_node=2 train.py --mini
This will resize Llama 3 into a model with 4 hidden layers and max-sequence-length reduced to 4K (4096). We have tested it with 2 x 48GB GPUs.
You may further shrink it if the model is still too large:
python train.py --prepare_data --max_seq_len=1024
torchrun --nproc_per_node=2 train.py --max_seq_len=1024 --num_hidden_layers=2 --from_scratch
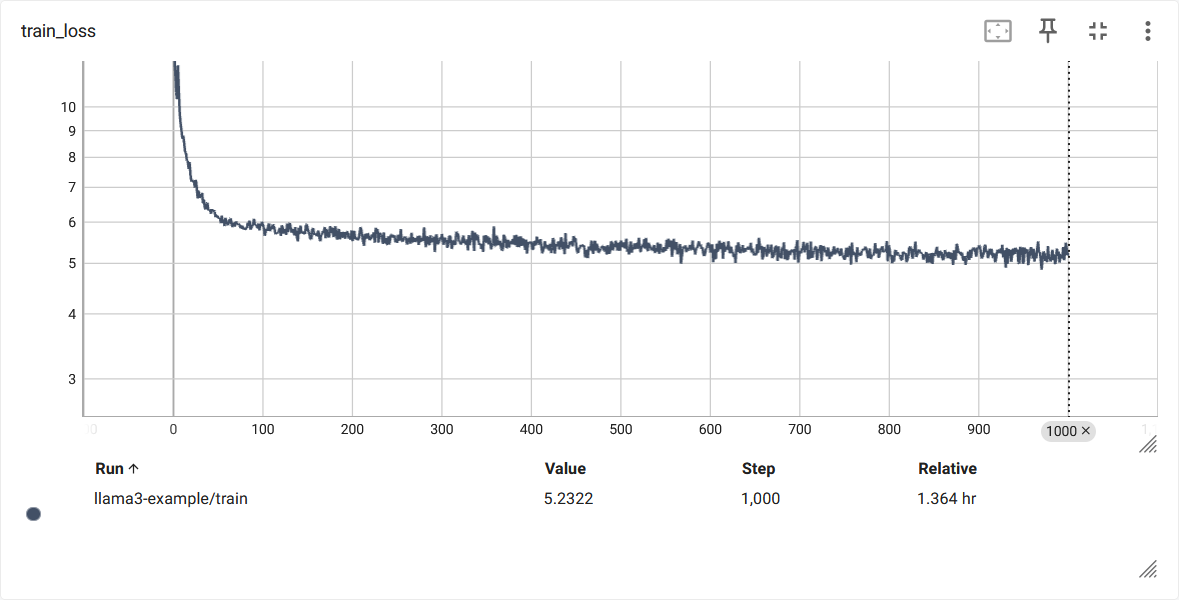
Here is the training loss with the default mini config (4 layers, 4K sequence length):
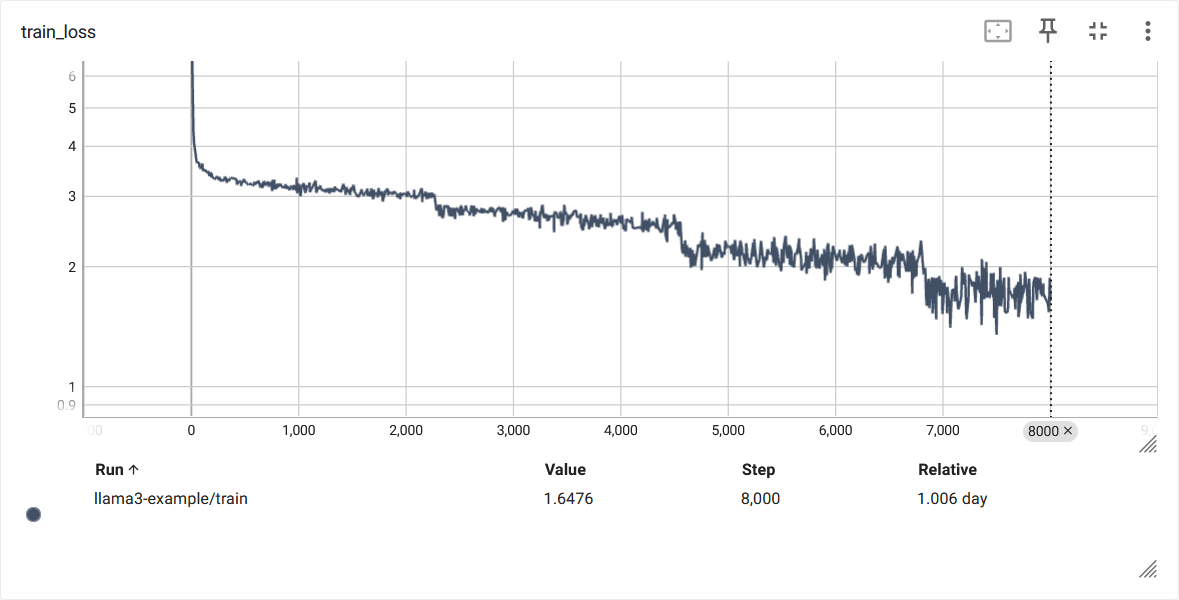
Finetune Llama 3 8B¶
Use the following commands to finetune Meta-Llama-3-8B-Instruct:
python train.py --prepare_data
torchrun --nproc_per_node=8 train.py
Resuming¶
The example will save checkpoint files after finishing 1000 steps then exit. To continue training from the saved checkpoint:
torchrun --nproc_per_node=8 train.py --resume_from=last --max_train_steps=2000
Please note that the checkpoint is sharded as multiple files. If you want to resume a checkpoint in a different environment, you need to merge it into an single checkpoint file first:
python train.py --merge_checkpoint=./checkpoints/last
torchrun --nproc_per_node=8 train.py --resume_from=./checkpoints/merged.ckpt --max_train_steps=3000